
Probabilistic Proofs (Shannon)
Abstract
This document describes the mechanism of Probabilistic Proofs, which is what allows Pocket Network to scale verifiable relay throughput to match an arbitrarily large demand. Precisely, it allows an unlimited number of sessions which pair (Applications and Suppliers for a given Service) by requiring the creation of a single on-chain Claim for each such session, but only probabilistically requiring an on-chain proof if its total reward amount is below a specific threshold.
External stakeholders (i.e. DAO/Foundation) need to be involved in adjusting the ProofRequirementThreshold by statistically analyzing onchain data, along with selecting an appropriate ProofRequestProbability that balances scalability and security. In turn, these values are used to derive on-chain reward and penalty amounts for honest and dishonest Suppliers, respectively. The penalty amount is then used to derive SupplierMinStake. Reasonably selected values can be chosen to easily scale the network by 100x without compromising security.
The results show that choosing a value of 20 POKT for ProofRequirementThreshold, the 95th percentile of all Claims, along with a ProofRequestProbability of 0.01, can enable 100x scalability of the network if the Slashing penalty for invalid/missing proofs is set to 2,000 POKT. As long as the minimum required stake for Suppliers exceeds this value, staked collateral will be available for slashing, if needed.
In future work, we will look at a potential attack vector that still needs to be considered, along with further research on the topic.
Relationship to Relay Mining
I think it may be worth noting that while probabilistic proofs reduce the number of on-chain proofs (block size), it will drive up supplier min stake amount as it's scaled. I think relaymining helps to mitigate this by taking the scaling pressure off of probabilistic proofs by reducing the size of each proof. Additionally, relaymining has the effect of minimizing the "max claim persistence footprint size":
RelayMining vs Probabilistic Proofs: negative correlation yields constant security guarantees ⛓️
Impacts:
proof requirement probability: decreases
threshold (limited by target percentile): increases
penalty: increases
num on-chain proofs: minimizes
Supplier min stake: maximizes
mining difficulty: increases
num on-chain claims (pruned over time): minimizes
size of on-chain proofs: minimizes
Scaling Up Relay Throughput (w/ respect to block size)
Problem Statement
tl;dr Too many on-chain Proofs do not scale due to state bloat and excessive CPU usage.
The core limiting factor to Pocket Network's scalability is the number of required on-chain Proofs. For details on how Proofs are generated and validated, see the Claim & Proof lifecycle section.
For every session (i.e. (Application, Supplier, Service) tuple), it is possible to construct a Merkle Proof which proves the Claimed work done, which can be stored on-chain.
These Proofs are large and costly to both store and verify. Too many Proofs result in:
State Bloat: Full Node disk space grows too quickly because blocks are large (i.e., full of transactions containing large Proofs), increasing disk usage.
Verification Cost: Block producers (i.e. Validators) MUST verify ALL Proofs (once), correlating average CPU usage with the average throughput of on-chain Proofs.
TODO_IN_THIS_PR: Reference the papers from Justin Taylor, Alin Tomescu, and Axelar (Avalanche?).
Example Scenario
Consider the hypothetical scenario below as an extremely rough approximation.
Network parameters:
Session duration:
1hourNumber of suppliers per session (per app):
20Number of services per session (per app):
1
Network state (conservative scenario):
Number of (active) services:
10,000Number of (active) applications:
100,000Number of (active) suppliers:
100,000
Assumptions for the purpose of an example:
Median Proof Size:
1,000bytesTotal time:
1day (24sessions)
Total disk growth per day:
10,000 apps * 1 Proof/(service,supplier) * 20 suppliers/app * 1 services/session * 24 sessions * 1,000 bytes/Proof = 4.8 GB ≈ 5 GBCRITICAL: A very simple (conservative) scenario would result in 5 GB of disk growth per day, amounting to almost 2 TB of disk growth in a year.
This discounts CPU usage needed to verify the Proofs.
High Level Approach
tl;dr Require a Claim for every (App, Supplier, Service) tuple, but only require a Proof for a subset of these Claims and slash Suppliers that fail to provide a Proof when needed.
Flow (conceptual):
Submit Claim
If Claim.ComputeUnits > Gov.ProofRequirementThreshold -> Proof Required (short-circuit)
Else: with probability Gov.ProofRequestProbability a Proof is required
If Proof required and Proof available and valid -> Distribute Reward
If Proof required and missing/invalid -> Slash Supplier Stake
If Proof not required -> Distribute Reward
(omitting random seed details)
Key Question
What onchain protocol governance parameters need to be selected or created to deter a Supplier from submitting a false Claim? How can this be modeled?
Guarantees & Expected Values
Pocket Network's tokenomics do not provide a 100% guarantee against gaming the system. Instead, there's a tradeoff between the network's security guarantees and factors like scalability, cost, user experience, and acceptable gamability.
Our goal is to:
Model the expected value (EV) of both honest and dishonest Suppliers.
Adjust protocol parameters to ensure that the expected profit for dishonest behavior is less than that of honest behavior.
A Supplier's balance can change in the following ways:
Earn rewards for valid Claims with Proofs (Proof required).
Earn rewards for valid Claims without Proofs (Proof not required).
Earn rewards for invalid Claims without Proofs (Proof not required).
Get slashed for invalid Proofs (Proof required but invalid).
Get slashed for missing Proofs (Proof required but not provided).
The goal of Probabilistic Proofs is to minimize the profitability of scenario (3) by adjusting protocol parameters such that dishonest Suppliers have a negative expected value compared to honest Suppliers.
Modeling an Attack
Defining a Single (Bernoulli) Trial
We use a Bernoulli distribution to model the probability of a dishonest Supplier getting caught when submitting false Claims.
Trial Definition: Each attempt by a Supplier to submit a Claim without being required to provide a Proof.
Success: A dishonest Supplier gets caught (i.e. is required to provide a Proof and fails, resulting in a penalty). (Taken from the network's perspective.)
Failure: A dishonest Supplier does not get caught (i.e. is not required to provide a Proof and receives rewards without providing actual service). Includes honest Suppliers being rewarded and all other outcomes. Does not include short-circuited Claims (i.e. Claim.ComputeUnits > ProofRequirementThreshold).
Conceptual Parameters: Onchain, Modeling, Governance, Etc
ProofRequestProbability (p): The probability that a Claim will require a Proof.
Penalty (S): The amount of stake slashed when a Supplier fails to provide a required Proof.
Reward per Claim (R): The reward received for a successful Claim without Proof.
Maximum Claims Before Penalty (k): The expected number of false Claims a Supplier can make before getting caught.
We note that R is variable and that SupplierMinStake is not taken into account in the definition of the problem. As will be demonstrated by the end of this document:
Reward per Claim (R) will be equal to the
ProofRequirementThreshold(POKT)Penalty (S) will be less than or equal to the
SupplierMinStake(in POKT)
Dishonest Supplier: Calculating the Expected Value
The dishonest Supplier's strategy:
Submit false Claims repeatedly, hoping not to be selected for Proof submission.
Accept that eventually, they will be caught and penalized.
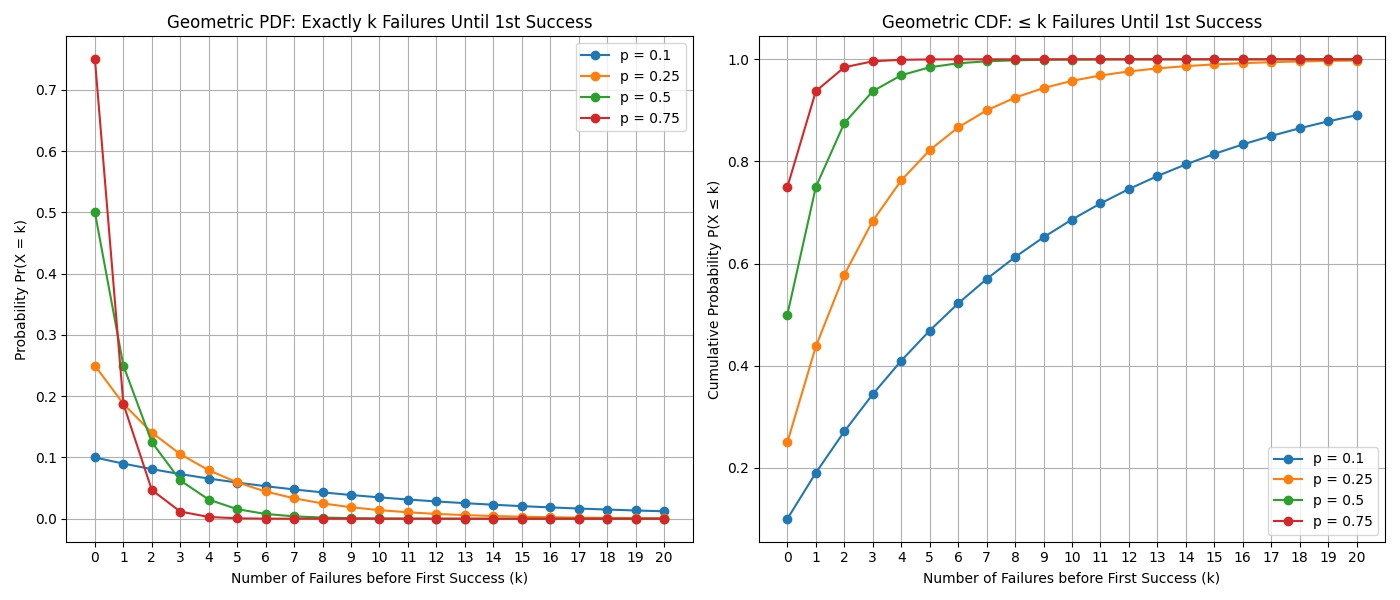
Modeling using a Geometric PDF
The number of successful false Claims before getting caught follows a Geometric distribution:
Probability of Not Getting Caught (q): q = 1 − p
Probability of Getting Caught on the (k+1)th Claim: P(X = k+1) = q^k · p
Expected Number of False Claims Before Getting Caught
E[K] = q / p
Modeling using a Geometric CDF
In practice, we often care about Pr(X ≤ k) — the probability of k or fewer failures before success — which is represented by the Geometric CDF. For simplification and clearer proof, the document uses the expected value from the Geometric PDF, which guarantees results at least as secure compared to directly using the CDF.
Total Rewards: Expected Value for Dishonest Supplier Before Penalty
E[Total Rewards] = R · E[K] = R · (q / p)
Expected Penalty
The penalty is a fixed amount S when caught.
Total Profit: Expected Value for Dishonest Supplier AFTER Penalty
E[Total Profit] = E[Total Rewards] − S = R · (q / p) − S
Honest Supplier: Calculating the Expected Value
Expected Rewards per Claim: E[Reward per Claim] = R
No Penalties: honest Suppliers always provide valid Proofs when required.
Expected Profit for Honest Supplier (1 Claim): E[Total Profit] = R
Setting Parameters to Deter Dishonest Behavior
We want: E[Total Profit_Dishonest] ≤ E[Total Profit_Honest]
Substituting: R · (q / p) − S ≤ R
Since q = 1 − p, this simplifies; requiring S to be sufficiently large. One useful choice that makes dishonest expected profit zero:
S = R · (q / p) = R · ((1 − p) / p)
With this choice: E[Total Profit_Dishonest] = R · (q / p) − S = 0
Example Calculation
Assume:
R = 10
p = 0.2
q = 0.8
Expected number of false claims before getting caught: E[K] = q / p = 0.8 / 0.2 = 4
Expected total rewards: E[Total Rewards] = R · E[K] = 10 · 4 = 40
Penalty: S = R · (q / p) = 10 · 4 = 40
Expected profit: E[Total Profit] = 40 − 40 = 0
The dishonest Supplier has expected profit 0, making dishonest behavior unattractive compared to honest behavior yielding R = 10 per Claim.
Generalizing the Penalty Formula
Set: S = R · (q / p) = R · ((1 − p) / p)
This makes the expected profit for dishonest behavior zero: E[Total Profit_Dishonest] = 0
TODO_IN_THIS_PR, incorporate feedback from Ramiro (summary):
Setting S to make expected profit 0 gives attacker no expected return but also no penalty; this allows spam since cost is 0.
Use of quantile (inverse CDF) for geometric distribution can set S higher so that in X% of attacks the attacker is punished (e.g., 95% -> higher S).
Example: for p = 0.01, using 95% quantile suggests S ~ 3x the zero-expected-return value (~6K POKT in earlier example), penalizing attacker with average loss across attacks. Source: https://gist.github.com/RawthiL/9ed65065b896d13e96dc2a5910f6a7ab
Considering false Claim Variance
While the expected profit may be 0, variance means attackers may be caught earlier (net loss) or much later (net profit). Variance must be considered when selecting S; increasing S or selecting S based on quantiles of the geometric distribution can reduce the probability of profitable large-outlier attacks.
Crypto-economic Analysis & Incentives
Impact on Honest Suppliers
Honest Suppliers are not affected by penalties since they always provide valid Proofs when required. Their expected profit remains: E[Total Profit_Honest] = R
TODO_IN_THIS_PR: Honest faulty suppliers will also be affected and penalized, which was not an issue before. Non-malicious faults (e.g. network outage) could cause penalties for honest Suppliers. This needs consideration.
Impact on Dishonest Suppliers
Dishonest suppliers face penalties that can erase anticipated profits, plus the probabilistic Proof requests add uncertainty and higher cost for dishonest behavior.
Analogs between Model Parameters and onchain Governance Values
Parameter Analog for Penalty (S)
tl;dr S = Supplier.MinStake
The penalty S is the amount the protocol should be able to retrieve from the Supplier. In practice, this is the Supplier.MinStake parameter, the amount a Supplier always has in escrow and that can be slashed.
Parameter Analog for Reward (R)
tl;dr R = Proof.ProofRequirementThreshold
For Probabilistic Proofs we assume a constant reward R per Claim because any reward greater than ProofRequirementThreshold requires a proof and short-circuits the probabilistic approach. Thus, R can be treated as constant when determining p and S.
Considerations during Parameter Adjustment
By tweaking p and S, the network can:
Increase deterrent against dishonest behavior.
Balance the overhead of Proof verification with security needs.
Considerations:
Lower
preduces number of Proofs required → improves scalability → requires higher penalties.Higher
Sincreases risk for dishonest Suppliers → may lead to participant pushback.High slashing penalties can also impact honest suppliers in the event of non-malicious faults.
Selecting Optimal p and S
To illustrate the relationship between p and S, see:
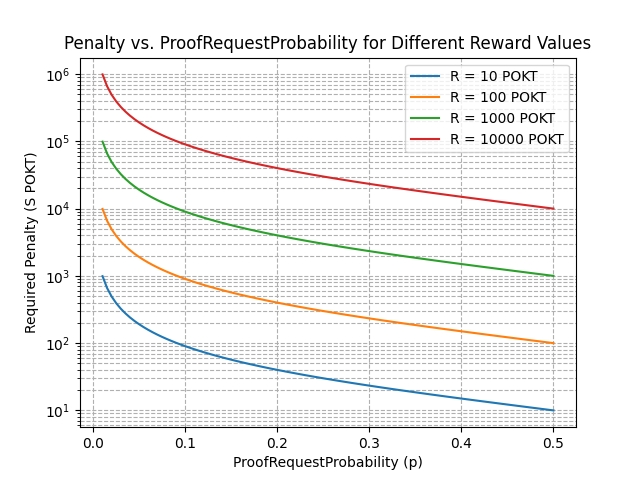
Considerations for Proof.ProofRequirementThreshold
Threshold Value: Set
ProofRequirementThresholdlow enough that most Claims are subject to probabilistic Proof requests, but high enough to prevent excessive Proof submissions.Short-Circuiting: Claims above the threshold always require Proofs, eliminating large false Claims slipping through.
Choose threshold so most Claims fall into the probabilistic bucket while balancing penalties that may be too large for faulty honest Suppliers.
Normal Distribution
If Claim rewards are approximately normal with mean μ and std σ, choose threshold ≈ μ + 2σ (≈ 97.3% coverage).
Non-Normal Distribution
In practice, rewards may be non-normal; choose a percentile (e.g., p95) such that 95% of Claims are in the probabilistic bucket.
Considerations for ProofRequestProbability (p)
The number of on-chain relays (proofs) required scales inversely with p:
p = 0.5 -> 2x scale
p = 0.25 -> 4x scale
p = 0.1 -> 10x scale
p = 0.01 -> 100x scale
p = 0.001 -> 1000x scale
Maximizing Pr(X ≤ k)
When selecting p, the goal is often to maximize Pr(X ≤ k) — the probability that a Supplier can have k or fewer failures (i.e., escape without penalty). This perspective complements expected-value calculations by controlling tail risk for attackers.
Conclusions for Modeling
By modeling attacks with geometric distributions and expected values, we can:
Determine R = ProofRequirementThreshold using onchain data.
Manually adjust p = ProofRequestProbability to tune scalability.
Compute S ≤ SupplierMinStake to deter dishonest behavior.
Ensure honest Suppliers remain profitable while dishonest Suppliers face negative expected profits.
This approach reduces on-chain Proof count while maintaining economic incentives to deter dishonest behavior.
Morse Based Value Selection
As of writing (October 2024), Shannon MainNet is not live; therefore, data from Morse must be used to approximate realistic values.
Selecting ProofRequirementThreshold
Choose R = 20 since it is greater than p95 of all Claims collected in Morse.
R = 20
Calculating p: ProofRequestProbability
Choose p = 0.01 to ensure high scalability.
E[K] = q / p = 0.99 / 0.01 = 99
Calculating S: ProofMissingPenalty
S = R · E[K] = 20 · 99 = 1980 ≈ 2,000
Above Threshold Attack Possibility
Investigate above-threshold attack possibilities:
Supplier may add fake serviced relays to the SMT and submit the claim. If the closest proof requested corresponds to: a. Fake relay -> Do not submit proof and face slashing. b. Legit relay -> Submit proof and be rewarded for fake relays.
This inflates the tree with fake relays and reduces the probability of being caught in proportion to fake relay ratio. This effect can be modeled as a reduced effective ProofRequestProbability; a security factor can be applied.
Future Work
Was this helpful?